Epilog ~ Kata Penutup ~
27 Mei 2018 Tinggalkan komentar
Setelah lama tidak mengunjungi situs blog sendiri, saya merasa ada yang perlu berubah. Salah satu contohnya adalah ukuran font yang terlalu kecil; seiring waktu berlalu, saya kini menggunakan monitor dengan resolusi yang lebih tinggi sehingga tulisan yang kecil semakin sulit dibaca. Berjalan pada plan gratis di WordPress.com, saya sama sekali tidak bisa melakukan modifikasi seperti perubahan CSS, menambahkan sedikit JavaScript dan sebagainya. Untuk melakukan itu semua, saya perlu beralih ke plan Premium atau Business. Oleh sebab itu, saya memutuskan untuk beralih ke penyedia baru yang memungkinkan saya berkreasi secara bebas.
Ingin fleksibilitas? Saya bisa menyewa server cloud seperti DigitalOcean, Linode, Heroku, AWS EC2 ataupun Google Compute Engine. Tapi semua itu tidak gratis (walaupun ada trial-nya)! Setelah memutar otak cukup lama, akhirnya saya memutuskan untuk menggunakan Github Pages. Walaupun hanya bisa melakukan hosting situs statis, Github Pages sudah mendukung HTTPS dan custom domain tanpa biaya sepeserpun. Saya pun segera membuat repository baru di GitHub yang dipergunakan sebagai source untuk situs yang dihasilkan.
Tidak dipungkiri memakai Jekyll untuk Github Pages tidak semudah di WordPress.com. Saya harus beradaptasi dengan struktur proyek dan format template yang dipakai.
Sesaat setelah menyiapkan proyek Jekyll, saya harus memilih salah satu themes untuk dipakai. Pilihannya tentu saja tidak sebanyak di WordPress.com. Namun, saya bisa melakukan kustomisasi sepuasnya bila ada bagian yang ingin saya ubah; cukup dengan dengan men-copy file di folder _layouts atau _includes milik theme ke proyek. Untuk sebuah situs yang berisi banyak tulisan untuk dibaca dalam jangka waktu lama, saya membutuhkan sebuah design yang sederhana tanpa banyak gangguan. Animasi indah dan gambar warna warni mungkin cocok untuk landing page yang berfungsi untuk menarik perhatian; namun sebagai pembaca yang sering menghabiskan waktu berjam-jam membaca dokumentasi, saya tahu betapa pentingnya menjaga agar pikiran bisa tetap konsentrasi pada tulisan 🙂 Oleh sebab itu, saya memakai theme bawaan, jekyll/minima. Saya hanya menambahkan Bootstrap 4.1 dan melakukan perubahan secukupnya. Hasil akhirnya dapat dilihat di https://blog.jocki.me.
Jekyll secara bawaan sudah memiliki fasilitas category dan tag. Tapi tidak lebih dari itu: ada beberapa fitur di situs WordPress.com yang harus dikorbankan. Salah satu contohnya adalah pencarian; perlu diingat bahwa Jekyll menghasilkan halaman statis dan tidak ada database untuk di-query. Salah satu solusinya adalah melakukan indexing saat Jekyll menghasilkan situs, kemudian ikut meng-upload index tersebut ke Github Pages, dan lakukan pencarian lewat JavaScript. Contoh implementasinya bisa dilihat di https://github.com/slashdotdash/jekyll-lunr-js-search. Catatan: Github Pages hanya mendukung plugin Jekyll tertentu saja! Karena tidak ingin terlalu repot, saya akhirnya memutuskan untuk menggunakan layanan Algolia pada plan bebas biaya (gratis). Untuk situs kecil yang jarang dikunjungi, saya pikir ini akan cukup. Cara saya menggunakan Algolia dan hasil akhirnya bisa dilihat di https://blog.jocki.me/pemograman/2018/05/18/memakai-algolia-untuk-fitur-pencarian-di-jekyll.
Karena sering menulis dengan topik yang berbeda-beda, saya sangat suka melihat tag cloud di blog ini untuk mengingatkan saya topik yang mana yang sudah terlalu sering dibahas dan mana yang jarang dibahas. Jekyll tidak menyediakan fasilitas serupa, tapi saya bisa menggunakan Highcharts untuk keperluan tersebut, seperti yang terlihat di https://blog.jocki.me/about. Fasilitas lain seperti arsip per bulan dan top posts terpaksa saya abaikan karena tidak ada plugin siap pakai yang kompatibel dengan Github Pages untuk mengimplementasikannya.
Sebenarnya theme jekyll/minima sudah menyediakan integrasi ke Disqus untuk komentar dan Twitter agar pengguna bisa men-follow. Akan tetapi saya tidak mengaktifkannya karena tujuan utama situs tersebut adalah sebagai jurnal pribadi. Saya adalah seorang yang pelupa; mencatat apa yang pernah saya lakukan akan membantu saya merekam aktifitas ke otak 🙂 Semua situs blog saya tidak pantas digunakan untuk referensi karena saya tidak pernah melakukan revisi pada artikel yang sudah diterbitkan.
Saya juga tidak sedang mempengaruhi pembaca untuk mengikuti metode saya. Ini adalah alasan mengapa saya jarang menggunakan kata “kamu” di blog saya. Preferensi dan metode pemograman seorang programmer selalu berubah sesuai dengan perkembangan zaman dan pengalaman programmer tersebut. Sebagai contoh, dulu saya senang mengembangkan aplikasi monolithic dengan Java Enterprise Edition. Tapi sekarang, saya lebih memilih microservices dan event driven. Mengapa preferensi saya berubah? Kebutuhan kinerja, dukungan infrastruktur cloud functions / lambda yang sederhana, serta kemampuan sisi klien yang semakin canggih (bandingkan Angular 6 dengan Backbone.js atau Knockout.js). Ada juga bagian yang belum berubah: misalnya, saya tetap percaya database relasional adalah yang terbaik untuk menyimpan domain classes untuk aplikasi enterprise. Tapi, sebagai alternatif, saya percaya bahwa menggabungkannya dengan database lain akan membuat database SQL semakin berguna. Misalnya untuk pencarian produk, saya menggunakan ElasticSearch dan untuk komentar dan audit log, saya menggunakan MongoDB. Dengan bantuan message queue yang baik, komunikasi antar database berbeda bukan merupakan hambatan melainkan jalan keluar untuk menghasilkan aplikasi yang memiliki kinerja sangat baik. Sepuluh tahun yang lalu saat saya masih berkutat dengan Oracle Database, saya sama sekali tidak membayangkan arsitektur seperti sekarang. Dengan teknologi dan pengalaman sepuluh tahun yang lalu, apa yang saya lakukan sekarang adalah sesuatu yang akan saya hindari saat itu.
Sekarang, setelah men-deploy situs blog yang baru, saya bisa bebas menambahkan JavaScript dan CSS. Sebagai contoh, pada https://blog.jocki.me/pemograman/2018/05/27/query-dns-lewat-https.html, saya membuat halaman yang memanggil Cloudflare DNS melalui HTTPS untuk men-resolve nama domain menjadi IP address. Halaman seperti ini tidak mungkin bisa saya buat bila tetap menggunakan WordPress.com pada plan gratis, karena WordPress.com hanya memungkinkan membuat artikel yang berisi tulisan, gambar dan video.
Sebagai penutup, karena ini adalah artikel terakhir pada blog ini, saya mencantumkan statistik halaman untuk situs ini pada saat tulisan ini dibuat:

Kunjungan Per Tahun
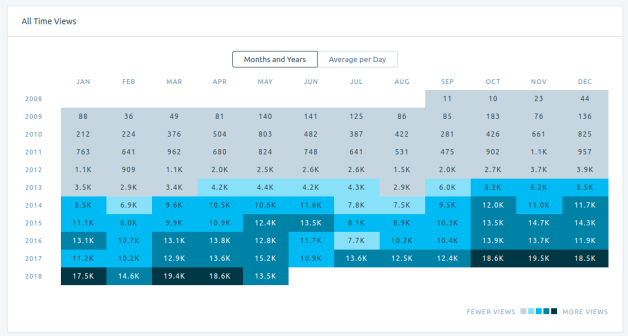
Tabel Kunjungan Per Tahun

Statistik Per Tahun

Artikel Yang Populer

Kunjungan Per Negara



















Anda harus log masuk untuk menerbitkan komentar.